Digital Transformation 2021 - hiểu rõ để làm tốt và tăng trưởng
•
4 gefällt mir•555 views

Digital Transformation 2021 - hiểu rõ để làm tốt và tăng trưởng

Empfohlen
Empfohlen
Weitere ähnliche Inhalte
Was ist angesagt?
Was ist angesagt? (20)
Ähnlich wie Digital Transformation 2021 - hiểu rõ để làm tốt và tăng trưởng
Ähnlich wie Digital Transformation 2021 - hiểu rõ để làm tốt và tăng trưởng (20)
Mehr von Duy, Vo Hoang
Mehr von Duy, Vo Hoang (20)
Kürzlich hochgeladen
Kürzlich hochgeladen (20)
Digital Transformation 2021 - hiểu rõ để làm tốt và tăng trưởng
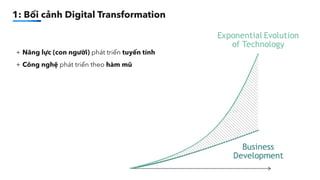
- 1. 1: Bối cảnh Digital Transformation + Năng lực (con người) phát triển tuyến tính + Công nghệ phát triển theo hàm mũ
- 2. #BCG Digital Transformation Framework * Số Hoá Core Domain * Số Hoá Quy trình Tăng trưởng * Con người và Tổ chức
- 3. #BCG Digitize Core Building Blocks * Data & Analytics * ML/DL * Blockchain Credit
- 4. #BCG Digitize Core Building Blocks - Domain Driven * Business Model Canvas * Customer Journey * Event Storming * Aggregate Credit
- 5. #BCG Digital Transformation Framework * Data & Analytics * ML/DL * Blockchain
- 6. #BCG Digitize Core Building Blocks * Apache Family * Domain-Driven Data Architecture Credit Technology is ready. Business needs domain experts to drive the implementation.
- 7. 1. Modern Business Intelligence Blueprint Query and Processing Output Predictive Historical Storage Sources Ingestion and Transformation OLTP Databases via CDC Connectors (Fivetran, Stitch, Matillion) Dashboards (Looker, Superset, Mode, Tableau) Embedded Analytics (Sisense, Looker, cube.js) Augmented Analytics (Thoughtspot, Outlier, Anodot, Sisu) App Frameworks (Plotly Dash, Streamlit) Custom Apps Ad Hoc Query Engine (Presto, Dremio/ Drill, Impala) Real-time Analytics (Imply/Druid, Altinity/ Clickhouse, Rockset) Applications/ERP (Oracle, Salesforce, Netsuite, ...) Data Modeling (dbt, LookML) Spark Platform (Databricks, EMR) Databricks/ Delta Lake, Iceberg, Hudi, Hive Acid Parquet, ORC, Avro Python Libs (Pandas, Boto, Dask, Ray, ...) Event Streaming (Confluent/Kafka, Pulsar, AWS Kinesis) Stream Processing (Databricks/Spark, Confluent/Kafka, Flink) Metadata Management (Collibra, Alation, Hive, Metastore, DataHub, ...) Quality and Testing (Great Expectations) Entitlements and Security (Privacera, Immuta) Observability (Unravel, Accel Data, Fiddler) Batch Query Engine (Hive) Event Collectors (Segment, Snowplow) Workflow Manager (Airflow, Dagster, Prefect) 3rd Party APIs (e.g., Stripe) File and Object Storage Logs Data Lake Data Warehouse (Snowflake, BigQuery, Redshift) Data Science Platform (Databricks, Domino, Sagemaker, Dataiku, DataRobot, Anaconda, ...) Data Science and ML Libraries (Pandas, Numpy, R, Dask, Ray, Spark, ... Scikit-learn, Pytorch, TensorFlow, Spark ML, XGBoost, ...) S3, GCS, ABS, HDFS
- 8. 2. Multimodal Data Processing Blueprint Query and Processing Output Predictive Historical Storage Sources Ingestion and Transformation OLTP Databases via CDC Connectors (Fivetran, Stitch, Matillion) Dashboards (Looker, Superset, Mode, Tableau) Embedded Analytics (Sisense, Looker, cube.js) Augmented Analytics (Thoughtspot, Outlier, Anodot, Sisu) App Frameworks (Plotly Dash, Streamlit) Custom Apps Ad Hoc Query Engine (Presto, Dremio/ Drill, Impala) Real-time Analytics (Imply/Druid, Altinity/ Clickhouse, Rockset) Applications/ERP (Oracle, Salesforce, Netsuite, ...) Data Modeling (dbt, LookML) Spark Platform (Databricks, EMR) Databricks/ Delta Lake, Iceberg, Hudi, Hive Acid Parquet, ORC, Avro Python Libs (Pandas, Boto, Dask, Ray, ...) Event Streaming (Confluent/Kafka, Pulsar, AWS Kinesis) Stream Processing (Databricks/Spark, Confluent/Kafka, Flink) Metadata Management (Collibra, Alation, Hive, Metastore, DataHub, ...) Quality and Testing (Great Expectations) Entitlements and Security (Privacera, Immuta) Observability (Unravel, Accel Data, Fiddler) Batch Query Engine (Hive) Event Collectors (Segment, Snowplow) Workflow Manager (Airflow, Dagster, Prefect) 3rd Party APIs (e.g., Stripe) File and Object Storage Logs Data Lake Data Warehouse (Snowflake, BigQuery, Redshift) Data Science Platform (Databricks, Domino, Sagemaker, Dataiku, DataRobot, Anaconda, ...) Data Science and ML Libraries (Pandas, Numpy, R, Dask, Ray, Spark, ... Scikit-learn, Pytorch, TensorFlow, Spark ML, XGBoost, ...) S3, GCS, ABS, HDFS
- 9. 3. AI and ML Blueprint Clients Data Sources (Data lake + data warehouse + streaming engine) Data Labeling (Labelbox, Snorkel, Scale, Sagemaker) Dataflow Automation (Airflow, Pachyderm, Elementl, Prefect, Tecton, Kubeflow) Query Engines (Presto, Hive) Feature Server (Tecton, Cassandra) Compiler (TVM) Feature Store (Tecton) Data Science Libraries (Spark, Pandas, NumPy, Dask) Experiment Tracking (Weights and Biases, Comet, MLflow) Model Registry (Algorithmia, MLflow, Sagemaker) Visualization (Tensorboard, Fiddler) Model Tuning (Sigopt, hyperopt, Ray Tune) ML Framework (Scikit-learn, XGBoost, MLlib) DL Framework (TensorFlow, Keras, PyTorch, H2O) Model Monitoring (Fiddler, Arthur, Arize) Distributed Processing (Spark, Ray, Dask, Distributed TF, Kubeflow, Horovod) RL Libraries (Gym, Dopamine, RLlib, Coach) Data Science Platform (Jupyter, Databricks, Domino, Sagemaker, DataRobot, H2O, Colab, Deepnote, Noteable) Model Inference Model Training and Development Data Transformation Batch Predictor (Spark) Online Model Server (TF Serving, Ray Serve, Seldon)
- 10. Data Visualization Data Connector (Sourcing) Data Engagement (Activation/Reporting) Data Security (Compliance) Streaming Processing Data Modeling Machine Learning Data Product (SQL) Query Provider Data Lake Batch Processing (2) (1) (1) (2) (2) (2) (1) Data Discovery + Ingest data from variety data sources help cut down your massive data set to a manageable size where you can focus your e ff orts on analyzing the most relevant data + Visualize data e ff iciency at scale + Agile process for explaining, exploration and deciding: segmentation or campaign orchestration (2) Data Engagement + Plug and Play any kind of Data Modeling either Statistical or ML Model + Engage Data-driven sta ff for making decision precisely + Campaign activation needs near-realtime data for better performance + Expose hidden-topic asap (3) Data Governance + Secure data + Re f ine Data Integrity + Personalization requires data- integrity Data Governance (3) (3) (2) Apache Bean Apache Hudi - Apache Atlas Presto Dagster - MLFlow Tensor f low/PyTorch Apache Ka f ka Apache Bean ReactJS Golang - Apache Karaf Elastic Search Clickhouse Apache Superset Cadence # Data Engine Block
- 11. Mô hình vận hành lõi về tăng trưởng (growth model) dựa trên nền tảng thực nghiệm và data. 2. PROCESS: MÔ HÌNH SCIENCE-BASED GROWTH ”data-driven & experiment-driven” là game changers của ”growth science”
- 12. Product Channel Model Market Model/Channel Fit Market/Model Fit Market/Product Fit Product/Channel Fit 2. PROCESS: MÔ HÌNH SCIENCE-BASED GROWTH
- 13. Product Channel Model Market Model/Channel Fit Market/Model Fit Market/Product Fit Product/Channel Fit 2. PROCESS: MÔ HÌNH SCIENCE-BASED GROWTH
- 14. Phân phối công nghệ ngày nay 3. Growth Science Views Objectives Strategy Tactic Performance Process Driven Technology Oriented Data Driven Business Oriented Marketing Manager Growth Hacker Innovation Leader Domain Expert Marketing Executive Product Manager Product Engineer Designer Marketing Analyst Data Scientist Business Analysis Domain Specialist Lean Plum Exponea Google Optimizely CleverTap Insider Holistic.io Looker Tableur KNIME Segment.io Appsflyer Adjust Branch CaptainGrowth CleverTap Insider Adobe Marketo
- 15. 4. Hệ sinh thái Công nghệ (gartner.com) Credit: https://gtnr.it/39hcrkR
- 16. Credit: Marketing Transit-Map by Gartner.com https://gtnr.it/39hcrkR Mobile Analytics CX Marketing Mgmt. HIGHLIGHT relevant zones
- 17. Mobile Analytics CX Marketing Mgmt. PROCESS DRIVEN OBJECTIVES + STRATEGY Credit: Marketing Transit-Map by Gartner.com https://gtnr.it/39hcrkR
- 18. Mobile Analytics CX Marketing Mgmt. PROCESS DRIVEN OBJECTIVES + STRATEGY Credit: Marketing Transit-Map by Gartner.com https://gtnr.it/39hcrkR
- 19. Mobile Analytics CX Marketing Mgmt. PROCESS DRIVEN OBJECTIVES + STRATEGY Credit: Marketing Transit-Map by Gartner.com https://gtnr.it/39hcrkR
- 20. Mobile Analytics CX Marketing Mgmt. PROCESS DRIVEN OBJECTIVES + STRATEGY Credit: Marketing Transit-Map by Gartner.com https://gtnr.it/39hcrkR
- 21. Mobile Analytics CX Marketing Mgmt. PROCESS DRIVEN OBJECTIVES + STRATEGY Credit: Marketing Transit-Map by Gartner.com https://gtnr.it/39hcrkR
- 22. Mobile Analytics CX Marketing Mgmt. PROCESS DRIVEN OBJECTIVES + STRATEGY Credit: Marketing Transit-Map by Gartner.com https://gtnr.it/39hcrkR
- 23. Mobile Analytics CX Marketing Mgmt. DATA DRIVEN PERFORMANCE + TACTIC Credit: Marketing Transit-Map by Gartner.com https://gtnr.it/39hcrkR
- 24. Mobile Analytics CX Marketing Mgmt. DATA DRIVEN PERFORMANCE + TACTIC Credit: Marketing Transit-Map by Gartner.com https://gtnr.it/39hcrkR
- 25. Mobile Analytics CX Marketing Mgmt. DATA DRIVEN PERFORMANCE + TACTIC Credit: Marketing Transit-Map by Gartner.com https://gtnr.it/39hcrkR
- 26. Credit: Marketing Transit-Map by Gartner.com Mobile Analytics CX Marketing Mgmt. DATA DRIVEN PERFORMANCE + TACTIC