R server and spark
•
2 gefällt mir•929 views

Microsoft R server for distributed computing โดย กฤษฏิ์ คำตื้อ Technical Evangelist Microsoft (Thailand) Limited ในงาน THE FIRST NIDA BUSINESS ANALYTICS AND DATA SCIENCES CONTEST/CONFERENCE จัดโดย คณะสถิติประยุกต์และ DATA SCIENCES THAILAND

Empfohlen
Empfohlen
Weitere ähnliche Inhalte
Was ist angesagt?
Was ist angesagt? (20)
Andere mochten auch
Andere mochten auch (20)
Ähnlich wie R server and spark
Ähnlich wie R server and spark (20)
Mehr von BAINIDA
Mehr von BAINIDA (20)
Kürzlich hochgeladen
Kürzlich hochgeladen (20)
R server and spark
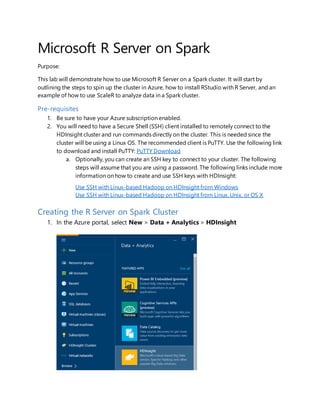
- 1. Microsoft R Server on Spark Purpose: This lab will demonstrate how to use Microsoft R Server on a Spark cluster. It will start by outlining the steps to spin up the cluster in Azure, how to install RStudio with R Server, and an example of how to use ScaleR to analyze data in a Spark cluster. Pre-requisites 1. Be sure to have your Azure subscription enabled. 2. You will need to have a Secure Shell (SSH) client installed to remotely connect to the HDInsight cluster and run commands directly on the cluster. This is needed since the cluster will be using a Linux OS. The recommended client is PuTTY. Use the following link to download and install PuTTY: PuTTY Download a. Optionally, you can create an SSH key to connect to your cluster. The following steps will assume that you are using a password. The following links include more information on how to create and use SSH keys with HDInsight: Use SSH with Linux-based Hadoop on HDInsight from Windows Use SSH with Linux-based Hadoop on HDInsight from Linux, Unix, or OS X Creating the R Server on Spark Cluster 1. In the Azure portal, select New > Data + Analytics > HDInsight
- 2. 2. Enter a name in the Cluster Name field and select the appropriate Azure subscription in the Subscription field. 3. Click Select Cluster Type. On the Cluster Type blade, select the following options: a. Cluster Type: R Server on Spark b. Cluster Tier: Premium Click Select to save the cluster type configuration. 4. Click Credentials to create the cluster login username and password and the SSH username and password. This is also where you can upload a key instead of using a username/password for SSH authentication. 5. Click the Data Source field. Create a new storage account and a default container for the cluster to use. 6. Click the Pricing field. Here you will be able to specify the number of Worker nodes, the size of the Worker nodes, the size of the Head nodes and the R server
- 3. node size (this is the edge node that you will connect to using SSH to run your R code). For demo purposes, you can leave the default settings in place. 7. Optionally, you can select External Metastores for Hive and Oozie in the Optional Configuration field if you have SQL Databases created to store Hive/Oozie job metadata. For this demo, this option will remain blank. 8. Either create a new Resource group or select an existing on in the Resource Group field. 9. Click Create to create the cluster. Installing RStudio with R Server on HDInsight The following steps assume that you have downloaded and installed PuTTY. Please refer to the Prerequisites section at the top of this document for the link to download PuTTY. 1. Identify the edge node of the cluster. To find the name of the edge node, select the recently created HDInsight cluster in the HDInsight Clusters blade. From there, select Settings > Applications > R Server for HDInsight. The SSH Endpoint is the name of the edge node for the cluster. 2. SSH into the edge node. Use the following steps to connect to the edge node:
- 4. a. To connect to the edge node, open PuTTY. The following is a screenshot of PuTTY when it is opened up: b. In the Category pane, select Session. Enter the SSH address of the HDInsight server in the Host Name (or IP address) text box. This address could be either the address of the head node or the address of the edge node. Use the address of the edge node to connect to the edge node and configure RStudio. Click Open to connect to the cluster.
- 5. c. Log in with the SSH credentials that were created when the cluster was created. 3. Once connected, become a root user on the cluster. Use the following command in the SSH session: sudo su - 4. Download the custom script to install RStudio. Use the following command in the SSH session wget http://mrsactionscripts.blob.core.windows.net/rstudio-server-community- v01/InstallRStudio.sh 5. Change the permissions on the custom script file and run the script. Use the following commands: chmod 755 InstallRStudio.sh ./InstallRStudio.sh
- 6. 6. Create an SSH tunnel to the cluster by mapping localhost:8787 on the HDInsight Cluster to the client machine. This can be done through PuTTY. a. Open PuTTY, and enter your connection information. b. In the Category pane, expand Connection, expand SSH, and select Tunnels. c. Enter 8787 as the Source port and localhost:8787 as the Destination. Click Add and then click Open to open an SSH connection. d. When prompted, log in to the server with your SSH credentials. This will establish an SSH session and enable the tunnel. 7. Open a web browser and enter the following URL based on the port entered for the tunnel: http://localhost:8787/ 8. You will be prompted to enter the SSH username and password to connect to the cluster.
- 7. 9. The following command will download a test script that executes R based Spark jobs on the cluster. Run this command from the PuTTY session: wget http://mrsactionscripts.blob.core.windows.net/rstudio-server-community- v01/testhdi_spark.r 10. In RStudio, you will see the test script that was just downloaded in the lower right pane. Double click the file to open it and click Run to run the code. Use a compute context and simple statistics with ScaleR A compute context allows you to control whether computation will be performed locally on the edge node, or whether it will be distributed across the nodes in the HDInsight cluster. 1. From the R console, use the following to load example data into the default storage for HDInsight. # Set the HDFS (WASB) location of example data bigDataDirRoot <- "/example/data" # create a local folder for storaging data temporarily source <- "/tmp/AirOnTimeCSV2012" dir.create(source) # Download data to the tmp folder remoteDir <- "http://packages.revolutionanalytics.com/datasets/AirOnTimeCSV2012" download.file(file.path(remoteDir, "airOT201201.csv"), file.path(source, "airOT201201.csv")) download.file(file.path(remoteDir, "airOT201202.csv"), file.path(source, "airOT201202.csv")) download.file(file.path(remoteDir, "airOT201203.csv"), file.path(source, "airOT201203.csv")) download.file(file.path(remoteDir, "airOT201204.csv"), file.path(source, "airOT201204.csv")) download.file(file.path(remoteDir, "airOT201205.csv"), file.path(source, "airOT201205.csv")) download.file(file.path(remoteDir, "airOT201206.csv"), file.path(source, "airOT201206.csv")) download.file(file.path(remoteDir, "airOT201207.csv"), file.path(source, "airOT201207.csv")) download.file(file.path(remoteDir, "airOT201208.csv"), file.path(source, "airOT201208.csv")) download.file(file.path(remoteDir, "airOT201209.csv"), file.path(source, "airOT201209.csv")) download.file(file.path(remoteDir, "airOT201210.csv"), file.path(source, "airOT201210.csv"))
- 8. download.file(file.path(remoteDir, "airOT201211.csv"), file.path(source, "airOT201211.csv")) download.file(file.path(remoteDir, "airOT201212.csv"), file.path(source, "airOT201212.csv")) # Set directory in bigDataDirRoot to load the data into inputDir <- file.path(bigDataDirRoot,"AirOnTimeCSV2012") # Make the directory rxHadoopMakeDir(inputDir) # Copy the data from source to input rxHadoopCopyFromLocal(source, bigDataDirRoot) 2. Next, let's create some data info and define two data sources so that we can work with the data. # Define the HDFS (WASB) file system hdfsFS <- RxHdfsFileSystem() # Create info list for the airline data airlineColInfo <- list( DAY_OF_WEEK = list(type = "factor"), ORIGIN = list(type = "factor"), DEST = list(type = "factor"), DEP_TIME = list(type = "integer"), ARR_DEL15 = list(type = "logical")) # get all the column names varNames <- names(airlineColInfo) # Define the text data source in hdfs airOnTimeData <- RxTextData(inputDir, colInfo = airlineColInfo, varsToKeep = varNames, fileSystem = hdfsFS) # Define the text data source in local system airOnTimeDataLocal <- RxTextData(source, colInfo = airlineColInfo, varsToKeep = varNames) # formula to use formula = "ARR_DEL15 ~ ORIGIN + DAY_OF_WEEK + DEP_TIME + DEST" 3. Let's run a logistic regression over the data using the local compute context. # Set a local compute context rxSetComputeContext("local") # Run a logistic regression system.time( modelLocal <- rxLogit(formula, data = airOnTimeDataLocal) ) # Display a summary summary(modelLocal)
- 9. 4. Next, let's run the same logistic regression using the Spark context. The Spark context will distribute the processing over all the worker nodes in the HDInsight cluster. # Define the Spark compute context mySparkCluster <- RxSpark() # Set the compute context rxSetComputeContext(mySparkCluster) # Run a logistic regression system.time( modelSpark <- rxLogit(formula, data = airOnTimeData) ) # Display a summary summary(modelSpark) ScaleR Example with Linear Regression and Plots This example will show different compute contexts, how to do linear regression in RevoScaleR and how to do some simple plots. It utilized airline delay data for airports across the United States. #copy local file to HDFS rxHadoopMakeDir("/share") rxHadoopCopyFromLocal(system.file("SampleData/AirlineDemoSmall.csv",package="RevoScaleR"), "/share") myNameNode <- "default" myPort <- 0 # Location of the data bigDataDirRoot <- "/share" # define HDFS file system hdfsFS <- RxHdfsFileSystem(hostName=myNameNode, port=myPort) # specify the input file in HDFS to analyze inputFile <-file.path(bigDataDirRoot,"AirlineDemoSmall.csv") # create Factors for days of the week colInfo <- list(DayOfWeek = list(type = "factor", levels = c("Monday","Tuesday","Wednesday", "Thursday","Friday","Saturday","Sunday"))) # define the data source airDS <- RxTextData(file = inputFile, missingValueString = "M", colInfo = colInfo, fileSystem = hdfsFS) # First test the "local" compute context rxSetComputeContext("local") # Run a linear regression system.time(
- 10. model <- rxLinMod(ArrDelay~CRSDepTime+DayOfWeek, data = airDS) ) # display a summary of model summary(model) # define MapReduce compute context myHadoopMRCluster <- RxHadoopMR(consoleOutput=TRUE, nameNode=myNameNode, port=myPort, hadoopSwitches="-libjars /etc/hadoop/conf") # set compute context rxSetComputeContext(myHadoopMRCluster) # Run a linear regression system.time( model1 <- rxLinMod(ArrDelay~CRSDepTime+DayOfWeek, data = airDS) ) # display a summary of model summary(model1) rxLinePlot(ArrDelay~DayOfWeek, data= airDS) # define Spark compute context mySparkCluster <- RxSpark(consoleOutput=TRUE) # set compute context rxSetComputeContext(mySparkCluster) # Run a linear regression system.time( model2 <- rxLinMod(ArrDelay~CRSDepTime+DayOfWeek, data = airDS) ) # display a summary of model summary(model2) # Run 4 tasks via rxExec rxExec( function() {Sys.info()["nodename"]}, timesToRun = 4 ) Wrap Up This lab was meant to demonstrate how to use Microsoft R Server on a Spark cluster. For more information, refer to the references listed in the References section. References 1. https://azure.microsoft.com/en-us/documentation/articles/hdinsight-hadoop-r- server-get-started/
- 11. Microsoft R server for distributed computing The First NIDA Business Analytics and Data Sciences Contest/Conference วันที่ 1-2 กันยายน 2559 ณ อาคารนวมินทราธิราช สถาบันบัณฑิตพัฒนบริหารศาสตร์ -แนะนํา Microsoft R Server -Distributed Computing มีวิธีการอย่างไร และมีประโยชน์อย่างไร -แนะนําวิธีการ Configuration สําหรับ Distributed Computing https://businessanalyticsnida.wordpress.com https://www.facebook.com/BusinessAnalyticsNIDA/ กฤษฏิ์ คําตื้อ, Technical Evangelist, Microsoft (Thailand) -Distributed computing กับ Big Data -Analytics บน R server -สาธิตและสอนในลักษณะ workshop Computer Lab 2 ชั้น 10 อาคารสยามบรมราชกุมารี 1 กันยายน 2559 เวลา 9.00-12.30